lab2 — 物理内存管理
前置知识
分段机制、分页机制、物理内存管理机制、伙伴系统、slub 分配算法。
改动点
相比于 lab1 源代码,lab2 主要做了如下改动:
bootasm.S增加内存探测功能借助于 BIOS 提供的
int 0x15中断功能,探测当前机器的内存布局,并将其结果放置于0x8000处。该结果以 地址范围描述符 结构体形式进行存放:
1
2
3
4
5
6
7
8struct e820map {
int nr_map;
struct {
long long addr; // 基址
long long size; // 大小
long type; // 类型
} map[E820MAX];
}kernel.ld重新设置入口点和加载位置在
lab1中,ucore 入口点直接为init.c;而在lab2中,ucore 入口点为entry.S,随后跳转至init.c,原因在于:需要在entry.S中完成开启分页机制、加载基本页表等工作。值得注意的是:虽然
kernel.ld中加载位置为0xC0100000,但是bootmian.c却将其实际加载至0x100000,从而形成一种不对等映射。增加
entry.S文件修改
pmm_init()函数该函数为实现物理内存管理的关键函数,所有练习均基于此进行展开,其中主要完成如下工作:初始化物理内存管理器
pmm_manager、内核空间虚拟地址与物理地址的映射、有关页目录表和页表的各种操作。
练习一
此练习用于了解 default_pmm.c 代码所做的工作 (默认的物理内存管理:基于 First-Fit 的连续物理内存分配算法)。
对于物理内存管理而言,主要涉及两大数据结构:
1 | // 该结构用于管理空闲物理内存。 |
熟悉此两大数据结构各字段含义和 First-Fit 思想,很容易理解 default_pmm.c 所做的工作,在此不再赘述。
值得一说的是:ucore 如何初始化 free_area_t?
初始化工作具体分为两部分:
init_pmm_manager()初始化物理内存管理器为
default_pmm_manager,并调用该管理器的init()以初始化free_list和nr_free。page_init()基于内存探测结果,将空闲物理块放置于
free_list中,以供管理器进行管理。鉴于此函数比较重要,在此简单列举其实现源代码 (已忽略部分无关代码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77static void page_init(void) {
// 之前放置内存探测结构的位置便是 0x8000 + KERNBASE,如今获取它。
struct e820map *memmap = (struct e820map *)(0x8000 + KERNBASE);
// maxpa 用于存放最大可用物理内存地址(注:ucore 设置可用物理空间最大为 KMEMSIZE,因此 maxpa 不可能超过此值,下面代码有设置)。
uint64_t maxpa = 0;
int i;
for (i = 0; i < memmap->nr_map; i ++) {
uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size;
// 如果内存块类型为 E820_ARM 表明,其可供 OS 使用。
if (memmap->map[i].type == E820_ARM) {
if (maxpa < end && begin < KMEMSIZE) {
maxpa = end;
}
}
}
if (maxpa > KMEMSIZE) {
maxpa = KMEMSIZE;
}
// kernel.ld 中 .bss 数据段的结尾,基本也属于 OS 代码部分的结尾。
extern char end[];
// 计算所含页数,设置页描述数组 pages 的起始位置。
npage = maxpa / PGSIZE;
pages = (struct Page *)ROUNDUP((void *)end, PGSIZE);
// 将 0~maxpa 部分的物理页,设为保留页。
for (i = 0; i < npage; i ++) {
SetPageReserved(pages + i);
}
// 页描述数组的结尾位置。
uintptr_t freemem = PADDR((uintptr_t)pages + sizeof(struct Page) * npage);
// 将 page table 结尾 ~ maxpa 空间放置于空闲链表内(目前仅涉及内核空间,后续 ucore 实验可能涉及用户空间)。
for (i = 0; i < memmap->nr_map; i ++) {
uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size;
if (memmap->map[i].type == E820_ARM) {
if (begin < freemem) {
begin = freemem;
}
if (end > KMEMSIZE) {
end = KMEMSIZE;
}
if (begin < end) {
begin = ROUNDUP(begin, PGSIZE);
end = ROUNDDOWN(end, PGSIZE);
if (begin < end) {
init_memmap(pa2page(begin), (end - begin) / PGSIZE);
}
}
}
}
/*
* QEMU 的物理内存探测结果布局:
* e820map:
* memory: 0009fc00, [00000000, 0009fbff], type = 1.
* memory: 00000400, [0009fc00, 0009ffff], type = 2.
* memory: 00010000, [000f0000, 000fffff], type = 2.
* memory: 07ee0000, [00100000, 07fdffff], type = 1.
* memory: 00020000, [07fe0000, 07ffffff], type = 2.
* memory: 00040000, [fffc0000, ffffffff], type = 2.
*
* 注:type 取值为 1,表示 OS 可用空间;type 取值为其他值,则 OS 不可用,仅供某些设备可用(具体不谈,知道即可)。
* 按照上述代码以及探测结果可知,最大可用空间为 [0~07fdffff],近似等于 [0~128M]。
*
* entry.S 中,设置基本页表 KERNBASE + (0 ~ 4M) ~ (0 ~ 4M) 的映射关系。
* 根据最开始的汇编代码可知:0~1M 已经供给 BIOS 和 BootLoader 使用,OS 使用的是 1~4M 空间。
* 这里就存在一个问题,重新设置页表前,OS 真的不会超过 4M 吗,即所需页面不会超过 3 * 1024 / 4 = 768?
* 简单分析一下:
* 运行代码查看 end 取值,可以发现其值为 0xc011bf28,刨去 BIOS 和 BootLoader 所占空间,可知:OS 代码、数据部分所占 27 个页面。
* page table 所需页面计算:128M = 128 * 1024 / 4 (32768) 页面 = 每个页面大致容纳 4K/20=200 个 page 信息,因此总共需要约 163 个页面。
* 由此可知,OS 是不会超过 4M 的。
*/
}
练习二
该练习用于了解页目录表、页表的使用,以及虚拟地址的转换流程。
对于 ucore 而言,如此划分 32 位的线性地址 (其中宏 PDX/PTX/PGOFF/PPN 分别用于获取线性地址的相应部分):
1 | // +--------10------+-------10-------+---------12----------+ |
对于页目录表或者页表而言,其均 4KB 对齐,且表项均为 int 整数 (因为 4KB 对齐,那么页表或页的物理地址的低 12 位一定为 0,那么表项可使用这低 12 位存放权限信息,例如,当前页表或页可读、可写、是否存在)。
get_pte() 函数的具体实现,详见源代码:
1 | pte_t * get_pte(pde_t *pgdir, uintptr_t la, bool create) { |
注意:函数参数、指针操作,所涉及的地址均为虚拟地址,而非实际物理地址。
练习三
该练习用于了解页目录表、页表的使用,以及虚拟地址的转换流程。
page_remove_pte() 函数的具体实现,详见源代码:
1 | page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) { |
扩展练习一
该练习用于熟悉并简要实现伙伴系统 (Buddy System)。
虽然没有完成这个练习,但是在此简单说明其实现原理。
对于伙伴系统而言,首先预备两个数据结构:
1 | // 设定总共存在 11 种不同大小的内存块,块大小分别为 2^0,...,2^10。 |
接下来,简要介绍主要操作:
init(void)与
default_init(void)类似,初始化两个数据结构。init_memmap(struct Page *base, size_t n)对于伙伴系统而言,每个空闲链表只能存放块大小为
2^i的块,因此需要将base拆分为合适的块,然后插入至相应的链表当中。alloc_pages(size_t n)首先寻找合适的
N = 2^i,使得N/2 < n <= N;然后从buddy_free_area[i]开始,向上找到一个空闲块,如果该块大于N,则需不断拆分,直至找到块大小刚好为N的空闲块 (拆分得到的其他块需放置到buddy_free_area合适的位置),并设置bitmap[i][]相应位置。free_pages(struct Page *base, size_t n)假定
n = 2^i,首先搜索bitmap[i][]以判断伙伴块是否空闲,如果是则需合并两者,随后递归执行free_page(base, n << 1),否则直接将其插入至buddy_free_area[i]即可,并设置bitmap[i][]相应位置。
伙伴系统的优点:较好地解决了外部碎片问题;适合大内存分配。
伙伴系统的缺点:性能开销偏大;如果所需内存偏小,则存在较严重的内部碎片。
扩展练习二
该练习用于熟悉并简要实现 slub 分配机制。
该练习同样没有完成,同样在此说明其实现原理。
slub 分配机制的整体框架如图所示 (基于分离适配思想、缓存思想而实现):
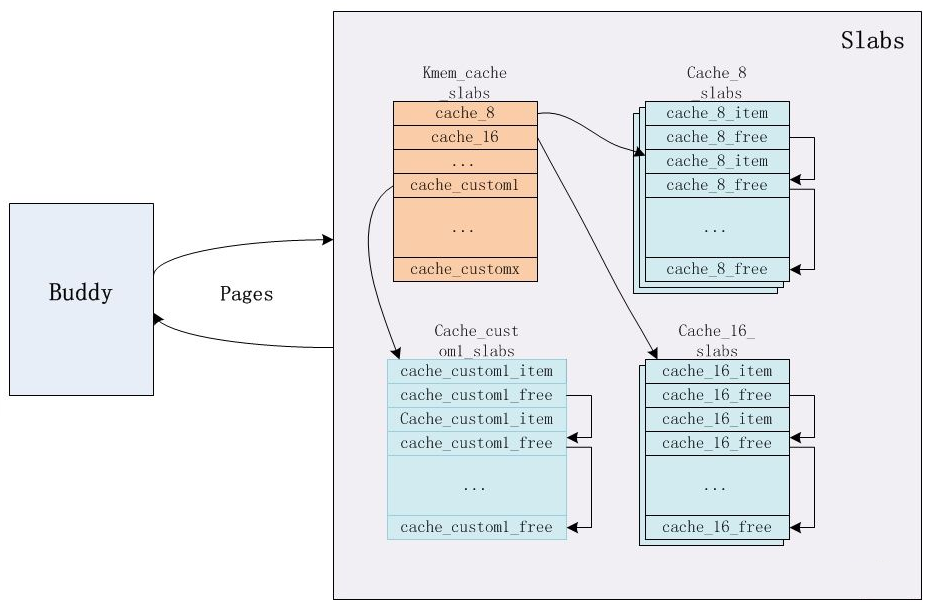
分离适配思想:指代将空闲块划分为若干类别进行存放,当请求特定大小的空闲块时,从指代类别中进行分配。伙伴系统、slub 分类机制、堆动态分配,都是基于此分配空闲空间的。
缓存思想:slub 分配机制基于底层的伙伴系统而实现,该思想指代当分配块释放后,并不直接将其返回给底层分配系统,而是将其缓存起来,等待后续分配使用。
在 slub 分配机制中,类别 (指代 kmem_cache) 划分为两类:通用型和专用型。前者所存放的空闲块大小依次为 8KB/16KB/…/8192KB (当所需块大小大于 8KB,则会直接使用伙伴系统进行分配),后者所存放的空闲块大小根据指定数据结构进行设定 (此一点应当是 slub 的最大亮点)。
1 | [root@VM-8-9-centos]# cat /proc/slabinfo |
类别指向一系列 slab,其中每个 slab 是由若干连续页组建得到的 object 集 (object 或已分配,或未分配),每次请求释放空间操作的主体对象便是 object。
slab 管理空闲
object的方式与堆动态内存分配管理空闲块的方式基本相同,都是在给定的空间内部利用空闲块存放相关链接信息。伙伴系统管理空闲块的方式则与它们并不相同,则是在另外某个特定地方存放相关链接信息 (对于 ucore 而言,存放于 page Table 中各 page 数据结构的链表结构中)。
slub 分配机制具体如何执行分配和释放 object 的操作,可详见 linux 内核 内存管理 slub算法 。
slub 分配机制的优点:有效解决小型内存分配问题、占用内存少。
地址映射的若干阶段
在 lab2 中,最为复杂的,莫过于与分段机制和分页机制相关的若干地址映射阶段,在此简要介绍其实现过程。
第一阶段
bootasm.S中开启分段机制,其所涉段表定义如下:1
2
3
4gdt:
SEG_NULLASM # null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # code seg for bootloader and kernel
SEG_ASM(STA_W, 0x0, 0xffffffff) # data seg for bootloader and kernel地址映射关系为:虚拟地址 == 线性地址 == 物理地址。
第二阶段
bootmain.c中加载 OS,由于编译的加载位置与实际的加载位置并不相同,因此存在一个隐性的地址映射关系 (实际并不存在):虚拟地址 - 0xC0000000== 线性地址 == 物理地址。第三阶段
entry.S中开启分页机制,其所涉页表如下:1
2
3
4
5
6
7
8.globl __boot_pgdir
# 映射虚拟地址 0 ~ 4M 至物理地址 0 ~ 4M(临时条目,跳转至 kern_init 前即会删除)。
.long REALLOC(__boot_pt1) + (PTE_P | PTE_U | PTE_W)
# 空白填充虚拟地址 4M ~ 0xC0000000 之间的页目录表项
.space (KERNBASE >> PGSHIFT >> 10 << 2) - (. - __boot_pgdir)
# 映射虚拟地址 0xC0000000 + (0 ~ 4M) 至物理地址 0 ~ 4M。
.long REALLOC(__boot_pt1) + (PTE_P | PTE_U | PTE_W)
.space PGSIZE - (. - __boot_pgdir)地址映射关系为:虚拟地址 == 线性地址 == 物理地址 + 0xC0000000 (仅限 0 ~ 4M)。
第四阶段
pmm_init() -> boot_map_segment()中重新设置页目录表和页表,从而得到如下地址映射关系:虚拟地址== 线性地址 == 物理地址 + 0xC0000000 (0~0x38000000,目前ucore所能访问的全部地址空间)。