处理器实现机制
概述
本文首先介绍处理器实现的底层基础,随后介绍单周期实现、流水线实现、乱序实现。
底层基础
对于处理器实现的底层基础而言,其由三部分组成:
基于组合逻辑设计实现指令集
在数字逻辑设计中,我们可以借助于基本逻辑门 (逻辑与、逻辑或、逻辑非) 实现各种复杂操作,由此形成的电路主要分为两种:逻辑电路 (输出结果仅与输入相关)、时序电路 (输出结果不仅相关于输入,而且相关于电路当前状态)。
基于逻辑门实现的电路与高级语言中的逻辑操作并不相同,其具有如下特性:电路输出结果持续响应输入信息;当输入信息发生变化后,经过一段电路时延,电路的输出结果也会随之变化。
注意:该特性使得时钟信号的存在十分有必要。
对于处理器实现的底层基础而言,其便是借助于各种逻辑设计电路实现既定体系指令集中各指令的功能。
基于时钟信号控制逻辑执行
我们先以时序电路为例说明现有电路所存在的问题。
下图的时序电路用于实现数据累加,register2 依次输入 1,2…,9,combinational logic 为数据累加的具体实现,register1 暂存累加值,最终结果输出至 Z。
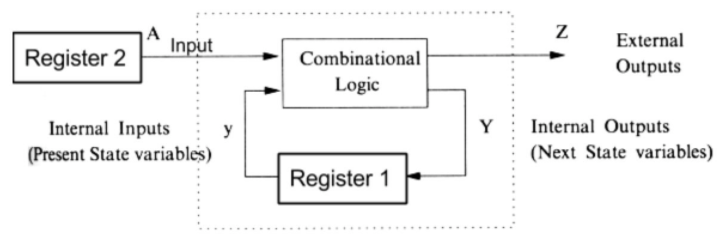
假定初始情况下一切输入输出均为 0,随后,register2 开始输出 1,经过一段时延,register 1 得到输入 1。此时做一设想:register1 立刻输出 1 而 register2 慢半拍。因为 combinational logic 输入发生变化,因此 register1 得到输入 2。
可以看到:此时 register1 计算已然不正确。这正是由于电路时延带来的危害,使得逻辑计算变得混乱。
究其根源,可以发现:根本原因在于 register1 不适时地得到输入并将其输出。
为解决这一问题,可以借助于时钟信号控制。对于 register 而言,作如下规定:只有当时钟信号上升沿来临时,才可将数据写入至 register 之中,其余时间均不可写入。
基于存储设备实现数据存储
所有存储设备的使用规则与上面的 register 相同,均是时钟信号上升沿来临时才可写入信息。
在此,我们介绍两种常见的存储设备:寄存器文件 (图左)、内存 (图右),其结构如图所示:
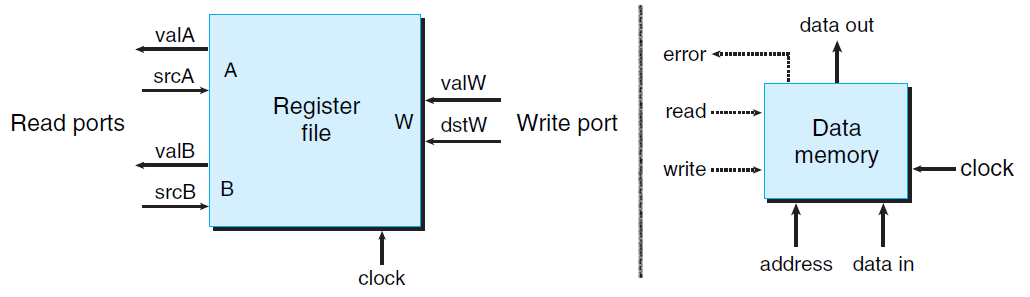
两者结构类似,我们以较为复杂的内存为例,作一简单说明。
当想要读取数据时,需自行设置 address/read,经过一段时延后,data out 即会输出待读取的数据信息;当想要写入数据时,需自行设置 address/data in/write,并且等待时钟信号上升沿来临时,数据才能写入至内存。
单周期实现
底层基础构建完毕后,我们开始实现最简单的处理器:单周期实现,即执行一条指令仅花费一个时钟周期。
为方便后续改进,在此将指令执行划分为如下阶段:
取指 (Fetch)
该阶段依据 PC 寄存器的值从内存读取指令字节。
译码 (Decode)
该阶段分析读取的指令字节,并从寄存器文件获取该指令所需的寄存器数据。
执行 (Excute)
该阶段依据指令功能,执行相关逻辑单元,以得到执行结果。
访存 (Memory)
该阶段可从内存获取数据,也可将数据写入内存。
写回 (Write back)
该阶段可将相关数据写入寄存器文件,以更新相关寄存器。
更新 PC
该阶段更新 PC 寄存器的值为下一条指令的地址。
单周期实现的结构如图所示:
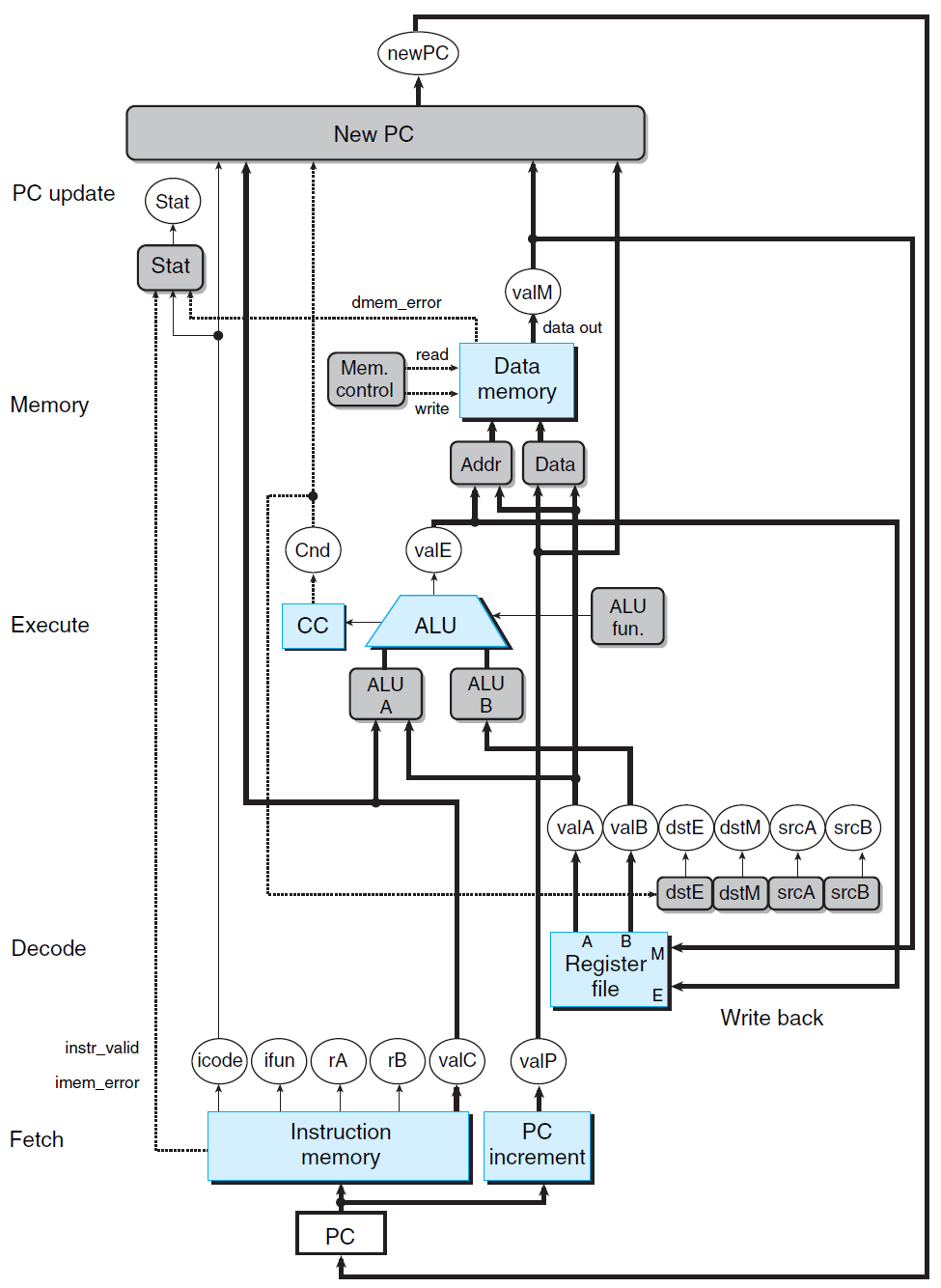
对于单周期实现而言,它能够实现指令执行,然而具有如下缺点:
- 因为需要将指令执行放置于一个时钟周期内,因此该时钟周期将会过长,这严重影响处理器单位时间内所能执行的指令数,从而使其处理性能低下。
- 在单个时钟周期内,指令执行的各阶段所涉硬件并不相同,从而出现某部分处于执行状态,而其他部分处于空闲状态。因此该种实现方式无法充分利用硬件。
流水线实现
流水线实现正是对单周期实现的改进,它可以做到进一步提升处理性能、充分利用硬件。
流水线实现的基本思想在于:划分指令执行为若干阶段,并借助于不相干的硬件部分处理各阶段。其结构如图所示:
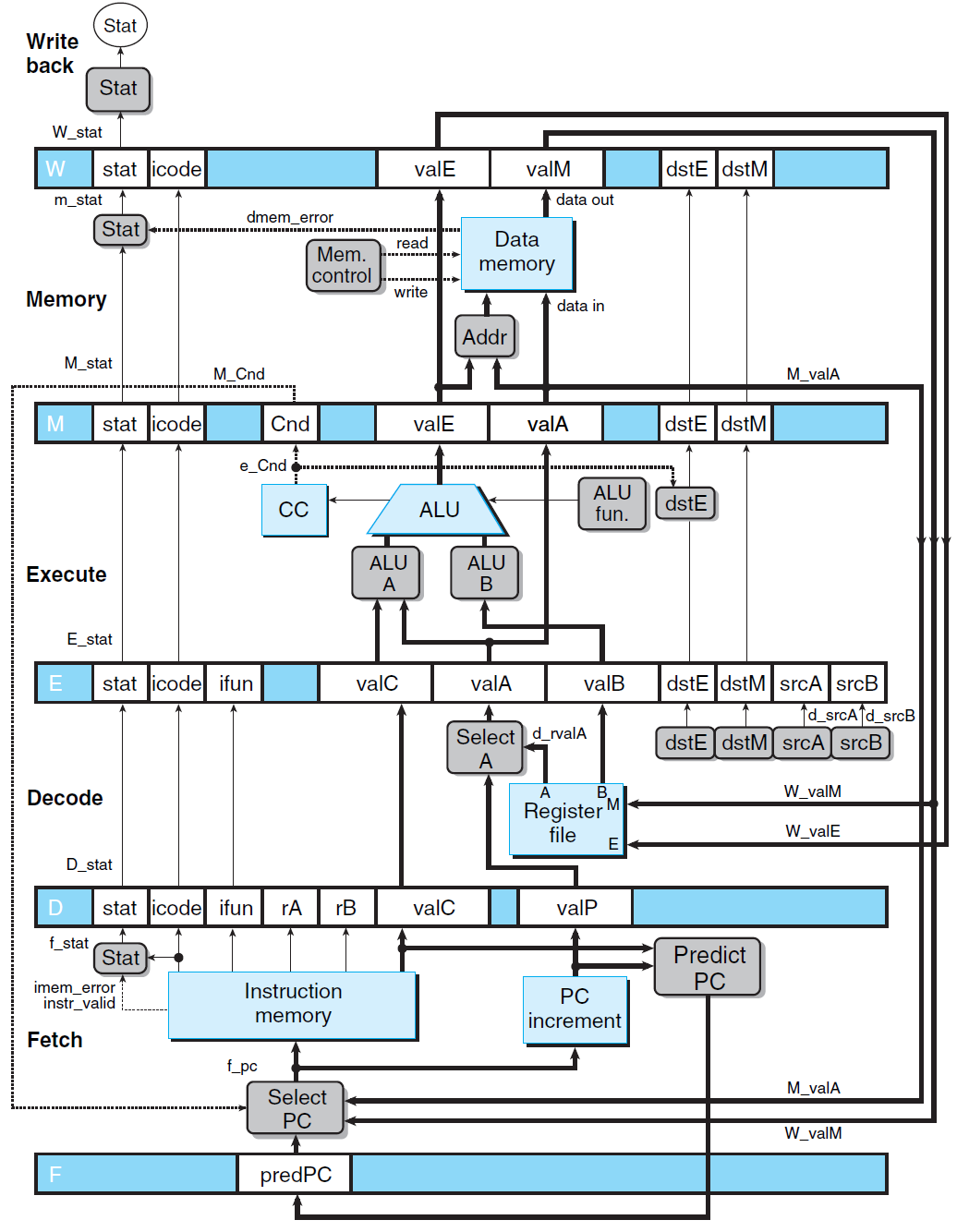
相比于单周期实现而言,其具有如下改动:
- 各阶段之间,借助于特殊寄存器暂存阶段执行结果,并以此作为下一阶段的输入信息。
- 一个时钟周期设定为各阶段执行所需时间的最大值。
- 融合取指和更新 PC 为同一阶段,如此便可实现连续取指。
更新 PC 实际操作比较麻烦。对于普通指令而言,只需执行 PC + 当前指令所占长度 即可;而对于指令 jxx (例如,jne)/ret 而言,需要借助于 分支预测技术 。
基于分支预测策略,分支预测技术可预测处理器即将执行哪个分支,从而更新 PC。最简单的分支预测策略即是:总是选择跳转、总是选择不跳转。
此时,指令执行过程类似如下 (其间存在数据冒险):
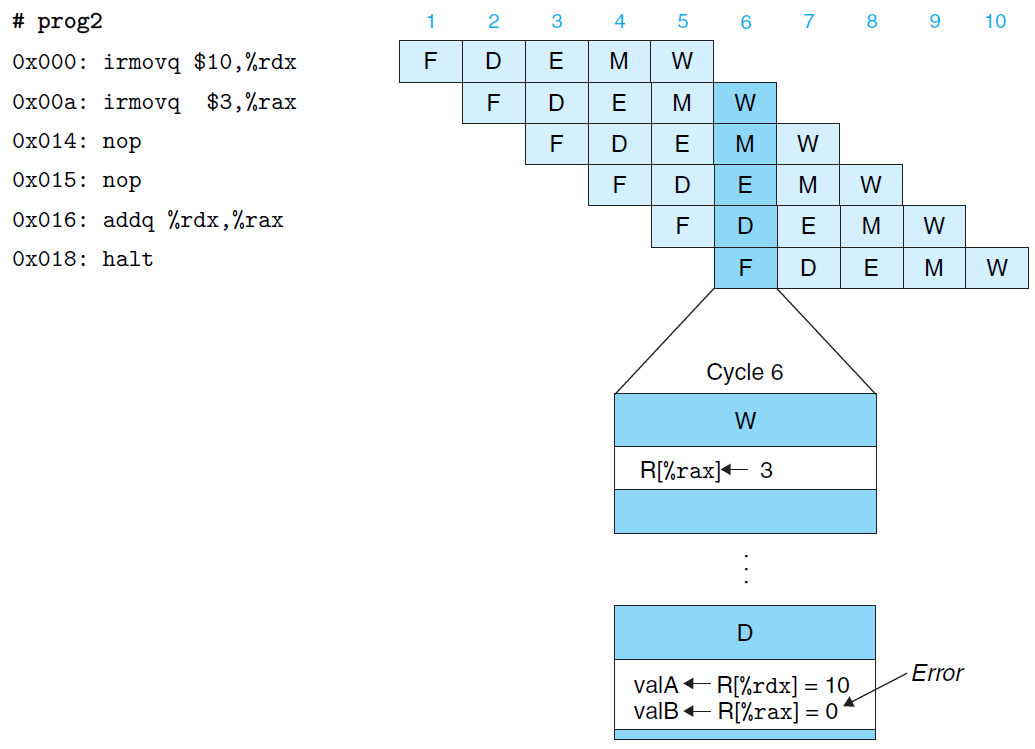
如此实现之后,其仍无法付诸实用。原因在于:虽然各阶段的执行硬件完全分离,但是指令之间却存在相关性。如此直接按序执行各阶段,而不施加相关操作,将会引发错误。
指令之间的相关性具体可细分为数据相关 (指代数据间读写相关) 和控制相关 (指代条件跳转引发的地址相关),由此引发的错误称为数据冒险和控制冒险。
数据冒险
指令间数据相关性具体表现为:RAR (读后读,即不同指令先后读取同一内容)、WAR (读后写,即某指令先写某内容,随后另一指令再读该内容)、RAW (写后读,即某指令先读某内容,随后另一指令再写该内容)、WAW (写后写,即不同指令先后写入同一内容)。
扯远一点,真正能够造成数据冒险的数据相关性为 RAW、WAW、WAR。而且在这三者之中,RAW 为真依赖,WAW 和 WAR 则是假依赖 (因为可借助于寄存器重命名技术消除此类依赖)。
因为计算机仅暴露有限的寄存器给编译器,因此编译器会重复使用这些寄存器构建汇编代码。实际实现之中,计算机内部还有其他寄存器可用,通过寄存器关系映射 (即寄存器重命名) 可实现消除此类依赖,并借助于相关机制以保证顺序执行。简单地举例而言,对于具有 WAW 数据相关的汇编代码
ADD r2,r1,r5; ADD r2,r3,r4;而言,使用寄存器重命名得到ADD P12,r1,r5; ADD P22,r3,r4;,如此即可并行执行,两者执行完毕后,借助于一定机制可保证将正确数据写入寄存器r2之内。对于 RAR 而言,单纯读取同一内容不会造成数据冒险;对于 WAR 而言,读操作位于 D 而写操作位于 M/W,当前指令的读操作一定位于下一条指令的写操作之前执行,因此其不会造成数据冒险;对于 RAW 而言,写操作位于 M/W 而读操作位于 D,下一条指令的读操作可能早于当前指令的写操作,因此其可能造成数据冒险;对于 WAW 而言,写操作要么均位于 M,要么均位于 W,因此其不会造成数据冒险。
综上分析可知:对于流水线实现而言,RAW 可能引发数据冒险。
为避免数据冒险发生,只需保证先前指令写操作完成后,才可执行当前指令的读取操作。
为实现此目的,具有两种实现方式:暂停执行 (图上)、数据转发 (图下),其实现示意如下:
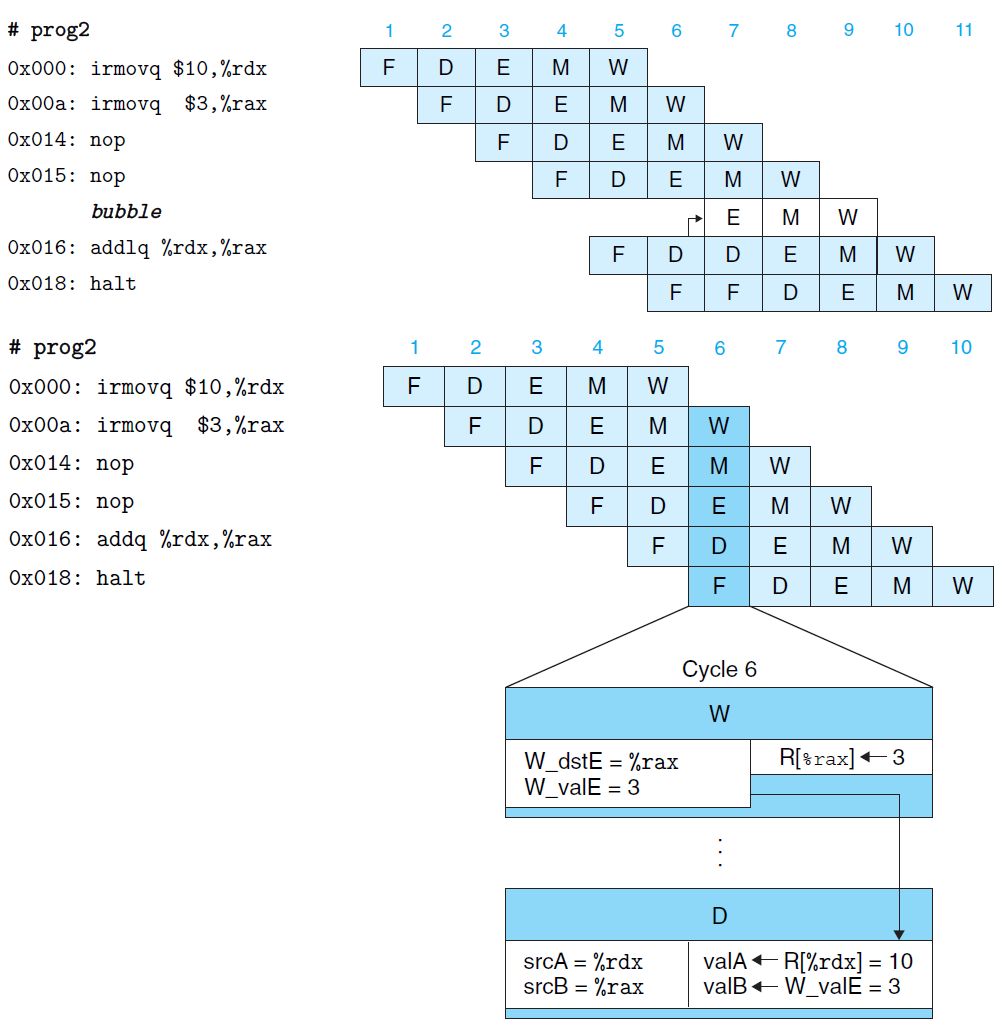
暂停执行:如果当前指令译码阶段所需读取数据与其上指令写入相关,则等待其上指令写入完成后,再开始执行当前指令的译码阶段。
数据转发:如果当前指令译码阶段所需读取数据与其上指令写入相关,则借助于相关逻辑控制,直接将执行、访存、写回阶段的数据转发给当前指令的译码阶段,从而使得当前指令顺利进入下一阶段的执行。
需要注意的是:暂停执行可解决所有的数据冒险,但是效率低下;数据转发无法解决所有的数据冒险,但是效率高。
数据转发无法解决的数据冒险称为 加载/使用数据冒险,即指代当前指令从内存获取数据至寄存器,而下一条指令立刻使用该寄存器。
为解决此类冒险,可联合使用暂停执行和数据转发,其实现示意如下:
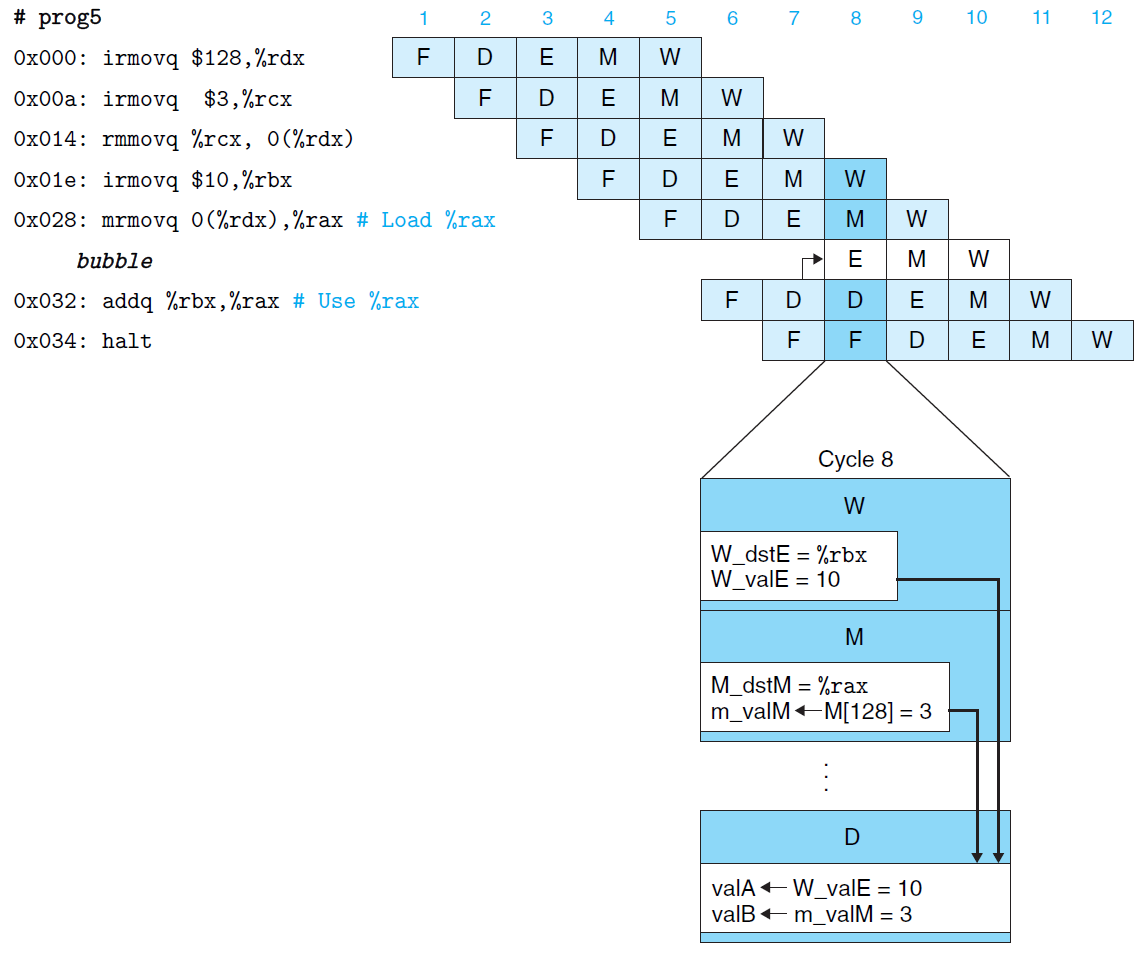
综上,对于一般数据冒险,流水线实现应当使用数据转发解决,对于加载/使用数据冒险,流水线实现使用 暂停执行 + 数据转发 解决,如此既可解决问题,又可提供高效率。
控制冒险
控制相关关注于条件跳转指令的执行,尤其是当分支预测错误后,应当如何解决以避免引发错误。
为解决控制冒险,计算机必须等待条件跳转指令执行完,确定分支后才能执行后续指令,因此其只能通过暂停执行加以解决,其实现示意如下:
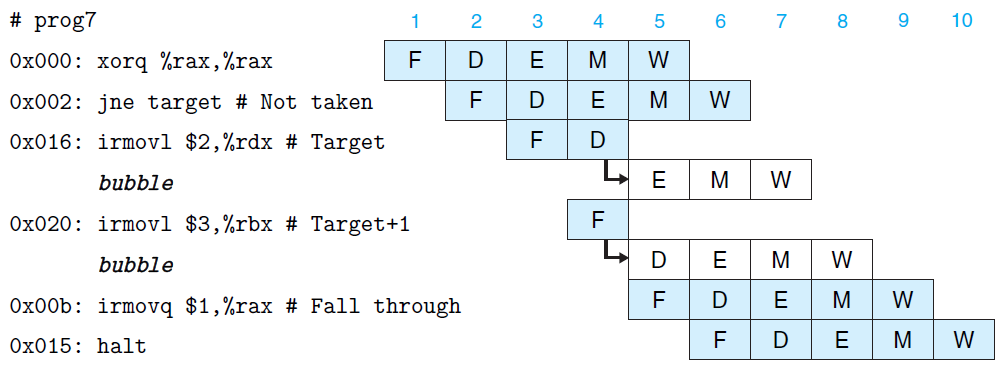
该实现具有一个小优化:当执行条件跳转指令时,其仍根据分支预测结果加载相关指令,只是将其暂停至译码阶段。如果分支预测成功,则直接译码然后执行即可;否则清空后续指令,然后加载指令分支指令执行即可。
通过为原有流水线实现添加冒险解决方案,如此便可付诸实用 (如果使用此时的流水线实现处理异常,其仍存在一些问题,但是并非主要内容,可以忽略)。
对于流水线实现而言,其性能瓶颈在于:如何平均划分指令执行各阶段,以使得一个时钟周期所需时间尽可能的小,从而提升处理器单位时间内所能执行的指令数。然而,由于指令执行的重头在于执行阶段,这使得各阶段实在无法实现平均划分,因此其他阶段都需要被迫等待,直至执行阶段完成。
乱序实现
乱序实现可以解决上面所谈及的流水线实现缺点,而且它向前更进一步,可以实现指令级并行 (指代一次处理多条无关指令)。其结构如图所示:
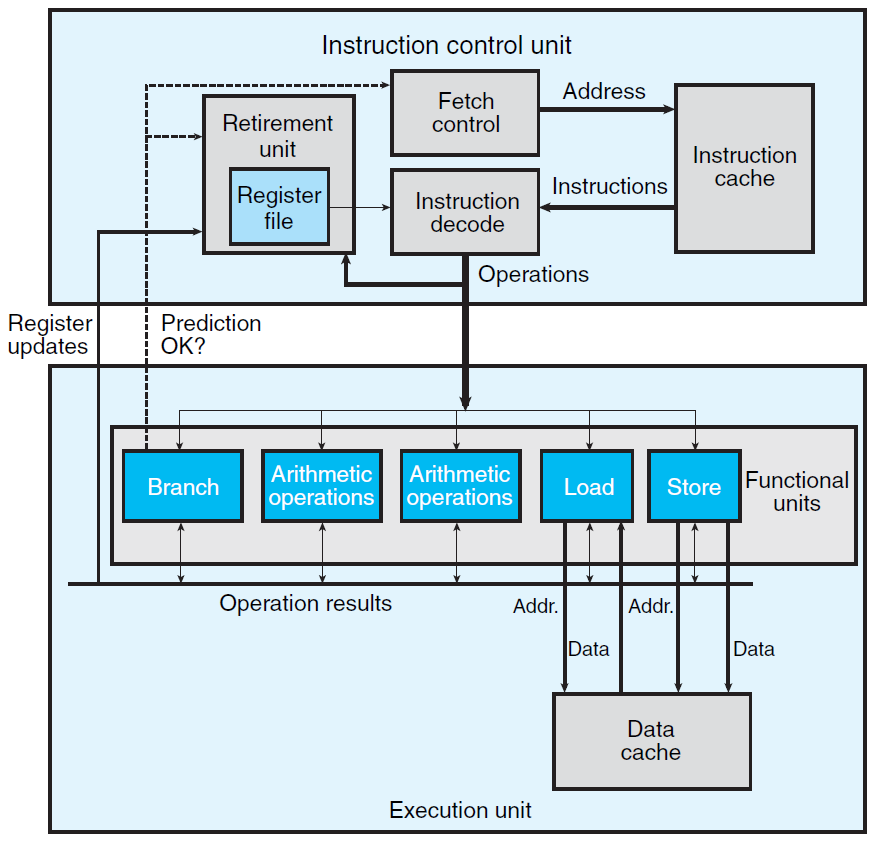
相比于流水线实现而言,其主要变动在于:为执行阶段提供多种、多个算术单元,从而为实现指令级并行提供可能。
就具体实现而言,两者之间亦存在差别:流水线实现中指令顺序执行,乱序实现中指令乱序执行。
简要说明乱序实现的指令执行流程:
- 指令控制单元 (ICU) 依次获取指令并对其译码,根据指令功能不同,将其发往不同的算术单元进行处理 (每个算术单元均有缓冲区存放指令)。
- 各算术单元接收指令后,如果该指令所需操作数已然获取,则待当前算术单元空闲时予以执行,随后发送执行结果至数据总线;反之,则监听数据总线以获取相关操作数。
- 各指令针对寄存器、内存所作的读写操作,也会基于一定机制实现更新相关内容。
乱序实现中,同样存在数据冒险和控制冒险,也自然具有相应机制加以解决,最为著名的便是:记分牌算法、Tomasulo 算法 (该算法便是借助于寄存器重命名技术解决 WAR 和 WAW 数据冒险的)。
需要注意的是:因为使用多个算术单元执行指令,因此乱序实现中的数据冒险涉及 RAW、WAW、WAR 三部分,而非仅仅 RAW。
鉴于乱序实现具有指令级并行特点,可借助于循环展开和设置多个累积变量以加快程序运行。
举例而言 (左侧为普通循环,右侧为 循环展开 + 设置多个累积变量):

为什么如此便可加快程序运行?原因有二:其一,各累积变量间计算互不相干,便可并行执行 (主因);其二,减少循环次数,从而避免少许因控制冒险引发的性能损耗 (辅因)。
程序运行性能相关于众多因素,如此单纯增加很多个累积变量,也有可能减缓程序运行,可能原因为:高速缓存内无法容纳全部指令代码,从而需要从内存获取,致使性能损耗。
其他
简单说明计算机为提升处理性能所做的相关工作:
- 借助于硅半导体工艺的精进,提升芯片的工作频率,从而增强单位时间内所能处理的指令数。
- 通过构建新的分支预测技术与乱序执行技术,增强乱序执行效率。
- 通过添加新的集成专用单元和相关指令 (例如 SSE,可实现向量数据的快速计算),增强处理器针对特定类型数据的处理能力。
- 借助于多核处理器 (即单个处理器内部存在多个性能较差的处理器核心),通过这些核心并行工作,以此达到高效率的处理性能,从而达到横向扩展计算机处理性能的目录。
就目前现状而言:1. 芯片工作频率已无法迅速提升,因为那样会导致功耗过大,得不偿失。2. 目前所用技术已能达到比较好的性能,增强乱序执行效率的空间并不大。3. 这方面工作做了很多工作,也没有提升空间。
因为性能较差的处理器核心仍存在提升空间,且目前已具有相当可观的提升速度,因此,目前唯一出路在于:使用多核处理器以提升处理器性能。