Linux 磁盘文件系统
概述
本文首先介绍 Linux 系统中最为常见的文件系统 ext2,随后介绍进阶文件系统 RAID 和 LVM。
磁盘分区完成后,还要经过格式化,系统才能使用此磁盘分区以存取数据。所谓格式化,即是在磁盘分区之上,构建一个文件系统。
Linux 系统所能识别的文件系统有 ext2 (Linux second extended file system)、xfs,Windows 系统所能识别的文件系统有 FAT (File Allocation Table)、NTFS (New Technology File System)。
如果将格式化为 NTFS 的磁盘分区挂载于 Linux 系统,Linux 系统是无法识别并使用此磁盘分区的。
ext2
Linux 系统所能识别的文件系统大体类似,我们在此介绍一种最为经典的文件系统 ext2。
在说明 ext2 结构之前,我们先介绍一下文件的存储形式。
对于一个文件而言,其主要分为两部分:实际存储内容和相关属性值 (例如,文件名、读写权限、修改时间等)。在 Linux 系统的文件系统之中,block 用于存储实际内容,inode 则用于存储相关属性值以及所对应的所有 block 编号。
当需要读取某文件的具体内容时,系统首先找到该文件对应的 inode,随后取出其中所有的 block 编号,最后提取各 block 内容以组合为该文件。其文件提取结构大致如下所示:
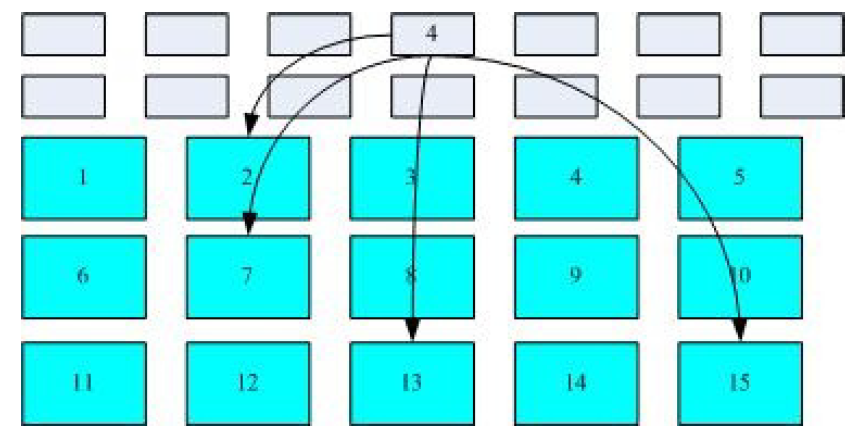
该种文件系统称为索引式文件系统,ext2 亦是此种文件系统。
接下来我们谈及文件系统 ext2 的实际结构,其结构具体如下:

对于一个磁盘分区而言,其先行被划分为一个 Boot Sector (用于存放开机管理程序) 和若干 Block Group。
划分分区为众多 Block Group 的目的在于便于管理,同时也可促使同一文件的各部分内容集中存放,加快读取速度。
对于一个 Block Group 而言,其进一步被划分为六部分:
Superblock
它用于记录文件系统的整体信息,具体包括
inode与block的总量、inode与block的块大小、文件系统的创建时间、是否挂载等。通常情况下,仅第一个 Block Group 具有此部分,其余 Block Group 均无此部分。为安全考虑,有时其他 Block Group 也会具有此部分,但是其内容仅为第一个 Block Group 此部分的备份。
档案系统描述
它用于记录当前 Block Group 所对应的开始和结束 Block 编号,以及 Block Group 内部六部分所对应的开始和结束 Block 编号。
区块对应表
基于 BitMap 数据结构,记录哪些
block处于空闲状态。inode 对应表
基于 BitMap 数据结构,记录哪些
inode处于空闲状态。inode table
存放具体文件所对应的
inode集。因为
inode之中存放该文件所对应的所有block编号,因此对于 ext2 文件系统而言,其所能存储的单个文件是有容量限制的。为尽可能扩大单个文件的容量限制,ext2 文件系统采用如下方式存放
block编号 (12 个直接记录、一个间接记录、一个双间接记录、一个三间接记录):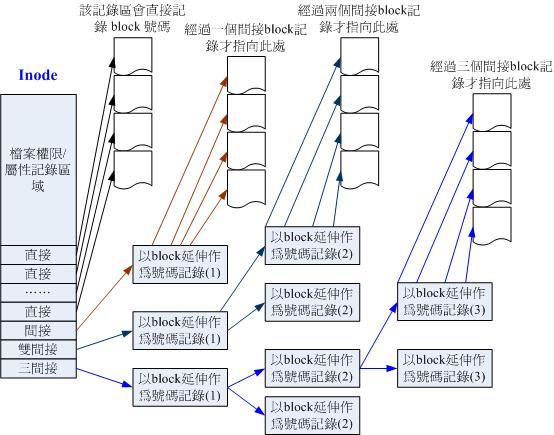
block table
存放具体文件所对应的
block集。
介绍完 ext2 文件系统结构之后,我们再谈两个问题:
如何查看 ext2 文件系统的结构参数信息?
Linux 系统提供指令
dumpe2fs以查看 ext2 文件系统的结构参数信息。ext2 文件系统是否存在数据不一致问题?
在 ext2 文件系统之中,读取操作不存在数据不一致问题,而写入操作可能引发数据不一致问题。
如果需要新增一个文件,文件系统将会产生如下行为:检查使用者对当前目录是否具有
wx权限 –> 根据inode bitmap找到空闲inode并写入属性信息 –> 根据block bitmap找到空闲block并写入文件内容 –> 更新inode/block bitmap与 Superblock。假定前三步顺利完成,随后断电使得第四步没有完成,此时便存在数据不一致问题。
为解决此问题,最初做法:基于 Superblock 中的挂载位和状态位等信息判断是否需要强制检查数据不一致问题,如果需要,则比对整个文件系统中
inode/block与bitmap、Superblock 中的信息,以此判断是否存在数据不一致问题。对于上述做法而言,它需要比对整个文件系统,故而十分耗时。为解决此问题,日志系统被应用至文件系统之中 —— 当需要写入文件至文件系统中时,首先向日志系统写入待操作信息,文件写入完成后,再次写入操作完成信息。此时,如果发生断电行为,再次开启系统后,只需检查日志系统即可判断是否存在数据不一致问题。
ext2 并不提供日志功能,而 ext3/4 可以提供日志功能。
最后,我们说明若干与此相关的指令:
df该指令可列出各文件系统的整体磁盘使用情况。
du该指令用于评估指定文件或目录所使用的磁盘空间大小。
ln该指令用于文件间链接。
链接具体分为实体链接和符号链接。实体链接,即硬链接,链接文件与实际文件的文件名不同,但是两者所对应的
inode相同;符号链接,即软链接,链接文件内部存放实际文件的具体路径,当查看链接文件时,系统会自动显示实际文件内容。需要注意的是:实体链接仅限于单一文件系统,且仅能供文件使用;符号链接不仅可供文件使用,也可供目录使用,而且可跨越多个文件系统,因此符号链接使用更为广泛。
RAID
借助于软件或硬件设备,RAID (Redundant Arrays of Inexpensive Disks) 可将多个小容量磁盘整合成为一个大容量磁盘,而且该大容量磁盘不仅具有 存储功能,也具有 数据保护功能。
根据 RAID 等级不同,其所具有的数据保护功能亦有所不同。常见的 RAID 等级如下:
在所有等级之下,RAID 均会先行设定 chunk 值,该值可理解为虚拟磁盘之上的扇区大小,它通常对应于物理磁盘之上的若干扇区。
RAID 具体实现技术及所涉算法比较复杂,故而不再做任何思虑。
RAID-0 (等量模式)
当写入文件之时,RAID 按照 chunk 大小切割文件,并将切割部分按序依次存入各磁盘之内,其结构大致如下:
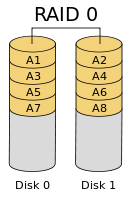
由于其中不含冗余信息,故而 RAID-0 不具有数据保护功能;但是它会将数据平均存于各磁盘之内,因此 RAID-0 具有最佳读写性能。
RAID-1 (映射模式)
当写入文件之时,RAID 按照 chunk 大小切割文件,并将文件内容分别写入各磁盘之中,其结构大致如下:
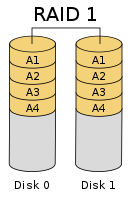
由于文件会被同时写入各磁盘之中,因此 RAID-1 具有最佳的数据保护功能;也正是如此,RAID-1 与普通单个磁盘的写性能相同,由于每个磁盘具有文件的全部数据,RAID-1 则可采用 RAID-0 类似的读取方式,使得 RAID-1 具有最佳的读性能。
RAID-5
RAID-5 属于 RAID-0 和 RAID-1 的折中方案,它借由奇偶校验信息以恢复数据。在该种 RAID 之中,即使一块磁盘发生损坏,所存储的数据信息也能得到恢复。
以下图结构为例:当写入数据之时,RAID 按照 chunk 大小切割文件,每次以 3 个 chunk 为一组,将它们及该 3 个 chunk 的奇偶校验结果随机放入各磁盘之中。
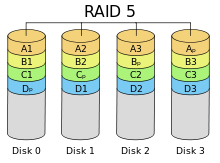
根据 RAID-5 的实现结构,可以看到:RAID-5 具有优于 RAID-0 的数据保护能力、近似等价于 RAID-0 的读写性能,且具有优于 RAID-1 的读写性能。
RAID-6
RAID-6 是对 RAID-5 的改进版本,它借由 2 块奇偶校验信息 (两者采用不同的奇偶校验算法) 以恢复数据。在该种 RAID 之中,它容许 2 块磁盘的损坏。
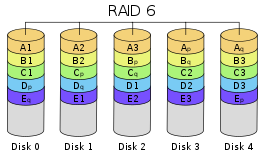
根据 RAID-6 的实现结构,可以看到:RAID-6 具有优于 RAID-5 的数据保护能力,近似等价于 RAID-5 的读写性能。
RAID-10
RAID-10 即是 RAID1+0,它将所有磁盘组合成为若干 RAID-1,再将这些 RAID-1 组合成为 RAID-0。
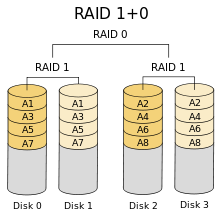
既然存在 RAID-10,一定会存在 RAID-01。
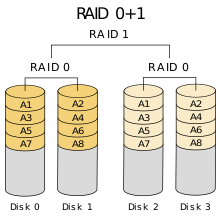
对于 RAID-10 和 RAID-01 而言,两者具有相同的读写性能,但是前者的数据保护功能强于后者的数据保护功能。
我们以例子说明关于数据保护功能的结论。对于 RAID-10 而言,假定 Disk0 损坏,则其余三个磁盘均可使用;而对于 RAID-01 而言,假定 Disk0 损坏,仅 Disk2 和 Disk3 可用。
实际使用之中,较常使用的等级为 RAID 10 和 RAID 6。
根据网上资料,在此说明不常使用 RAID 5 的原因:由于磁盘存在不可恢复读取错误 (URE, unrecoverable read error),当其中 1 块磁盘损坏后,RAID5 重建成功概率偏低,这使得数据丢失的风险增大。
若干注意点:
依据实现方式不同,RAID 可进一步划分为硬件 RAID 和软件 RAID。
软件 RAID 依赖于软件
mdadm而实现,具体借由指令mdadm实现创建、调整、删除、查询。构建 RAID 之时,通常会向其中加入若干 Spare Disk,以实现某些硬盘损坏时自动重建 RAID。
LVM
LVM (Logical Volume Manager) 能够整合多个磁盘分区,使其看上去就像一个大磁盘,而且能够实现动态增加或移除分区到该磁盘之中,以此实现 动态调整文件系统容量的功能。
在 LVM 之中,存在如下若干概念:
PV (Physical Volume)
它是 LVM 最底层的组成部分。
先借助于指令
fdisk将磁盘分区或磁盘设备的 UUID 修改为8e码 (LVM 的识别码),随后借助于指令pvcreate可将该磁盘分区或磁盘设备转换为 PV。VG (Volume Group)
将若干 PV 整合在一起,得到的便是 VG,它就是 LVM 整合得到的大磁盘。
PE (Physical Extent)
PE 概念等价于实体磁盘的扇区,也等价于 RAID 的 chunk,它是 LVM 中数据存储的最小单位。
LV (Logical Volume)
在 LVM 中,VG 是整合得到的大磁盘。为使用该大磁盘,必定需要进行分区,VG 分区得到的便是 LV。
根据上述概念,基本可以知道:LVM 首先抽象化 PV 得到 VG,随后在此基础之上,进行分区得到 LV,最后系统挂载 LV 进行使用。
VG、LV、PE 三者的关系可用下图加以表示:
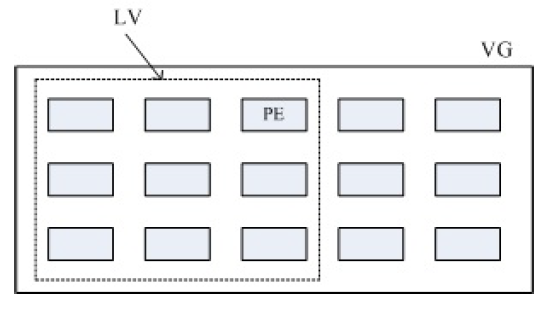
借助该图,LVM 能够实现动态调整文件系统容量的原因也可窥探一二。 LVM 的此项功能其实等价于能够实现动态调整 LV 和文件系统的容量,通过借用或退还 VG 中的 PE 可实现动态调整 LV 容量,而通过添加或减少 Block Group,同时修改部分配置信息即可实现动态调整文件系统容量。
在 LVM 之中,另有两个十分有趣的功能,分别为 “LVM thin Volume” 和 LV 磁盘快照,下面依次介绍之。
考虑这样一种情景:假定你需要 3 个 10G 的磁盘进行某些测试,而且这些磁盘的使用率都不会超过 10%,现如今你手边仅有一个 5G 的磁盘可用,那么能否借助于 5G 的磁盘仿真出 3 个 10G 的磁盘?“LVM thin Volume” 便可以做到这一点。
我们简单说明 “LVM thin Volume” 的实现原理:借助于 LVM 先行创建一个可以实支实付、用多少容量才分配实际写入多少容量的磁盘容量储存池 (thin pool),然后使用此磁盘容量存储池即可生成若干个 “指定固定容量大小” 的 LV 设备,这样就可解决此情景问题。
注意:基于磁盘容量存储池生成的 LV 设备的实际磁盘使用总量不能超过磁盘容量存储池的容量。
考虑这样一种情景:假定需要保存磁盘某刻状态,并在将来某个时刻恢复到此状态,应当如何解决?使用 LV 磁盘快照即可。
我们简单说明 LV 磁盘快照的实现原理:LVM 内部预留一个区域用于快照,将其暂称为快照区,LV 中的所有区域暂称为系统区,快照区与系统区共享系统区内部 PE。假定某时刻启动一个快照,则快照区内部用于存储此快照信息。如果系统区中所有 PE 未发生任何变动,由于共享关系,快照区所看到的便是快照状态;如果系统区中某些 PE 发生变动,则 LV 会将修改前的此 PE 放置于快照区之中,由于共享关系,快照区所看到的便是快照区信息与系统区信息的叠加结果,其仍为快照状态。该原理可简单使用下图表示:
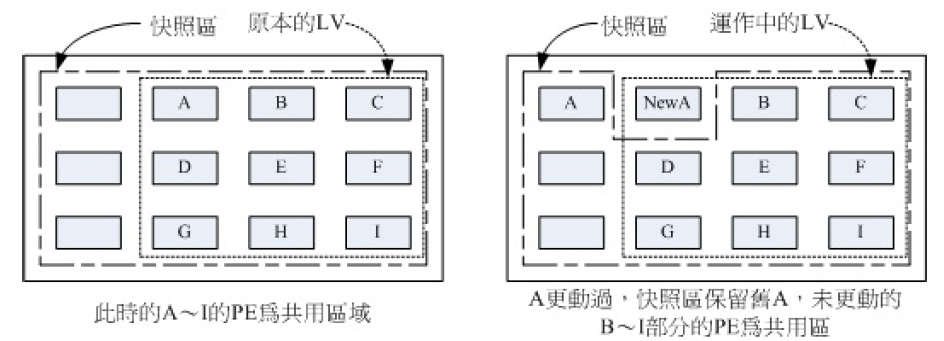
注意:快照区与系统区必须位于同一 VG。
LV 磁盘快照与普通认知中的快照还是有些不同的。当为某 LV 创建磁盘快照后,该快照表现为一个设备,它可以同普通设备一般进行使用 (使用原理:如果操作结果使得系统区内数据发生变动,则其会将系统区内该 PE 存储到快照区之中)。既然如此,便会引申出一种骚操作:以 LV 为基础内容,创建快照设备,并以此作为联系测试之用,如此即可快速创建多个测试环境。