git 基本原理
概述
本文简要介绍 git 版本控制系统的内部工作原理。
在介绍具体工作原理之前,需要声明如下几点:
- 从本质来讲,Git 是一个 内容寻址 (content-addressable) 文件系统,其核心部分是一个简单的键值对数据库 (key-value data store)。当我们向 Git 中插入任意类型的数据时,它以键值对方式存储该数据,并返回一个唯一标识的键值,借助于该键值,我们可引用至该数据。
- Git 提供两种指令 —— 上层指令和底层指令,上层指令允许我们以更友好地方式使用版本控制系统,底层指令帮助我们以更直观地方式理解版本控制系统。故而,此节之中会涉及若干底层指令。
Git 目录
当在一个空目录下执行 git init 命令时,Git 会创建一个 .git 目录,该目录几乎包含了 Git 存储和操纵所需的任何内容。.git 目录中各文件或文件夹的具体作用列举如下:
1 | config ==> 本地库配置相关内容。 |
接下来,我们主要介绍标识为 “(重点)“ 的文件或文件夹,它们均为 Git 的核心内容。
objects 目录
ojbects 目录存储所有数据内容,具体包括 git object、tree object、commit object、tag object。正因其存储数据,Git 的键值对数据库本质在此体现地淋漓尽致。
我们首先依次介绍 git object、tree object、commit object 、tag-object。由于它们在目录 objects 中存储形式一致,所以我们仅在 git object 中展现各种操作完成后的目录情况。另外,由于数据存储仍涉及其他具体操作,故而我们在 对象存储 一节中详细描述存储过程,并在此节中介绍 objects 目录中两个子目录 info 和 pack 的作用。
git object
git object 用于存储 Git 数据对象。底层命令 git hash-object 可将任意数据保存于 objects 目录,并返回与其相关的唯一标识。
我们首先说明 objects 目录情况:当前目录下存在两个空目录 —— info 和 pack。
控制台输入 echo 'test content' | git hash-object -w --stdin (参数 -w 表示获取对应散列值并将其存入 Git 数据库),它将手动创建一个数据对象并基于命令 git hash-object 将其存入 Git 数据库中,随后控制台输出如下内容,它为此数据对象的唯一标识,其本质是一个 SHA-1 散列值。

此时我们查看 objects 目录情况:当前目录下存在两个空目录 —— info 和 pack、一个子目录 d6,且子目录 d6 中存储二进制文件 70460b4b4aece5915caf5c68d12f560a9fe3e4。
根据 objects 目录情况,可以总结得到:Git 将待存储数据映射为一个 SHA-1 散列值,并以此散列值的前 2 个字符作为子目录,后 38 个字符作为文件名重新命名待存储数据。
为进行验证,我们可以使用底层命令 git cat-file -p <hash> (参数 -p 表示自动推断内容类型并大致显示其结果)查看指定键值所对应文件内容:

接下来,我们使用如下命令,向当前目录中添加一个文件并将其存入 Git 数据库、随后修改此文件,同时将其存入 Git 数据库:
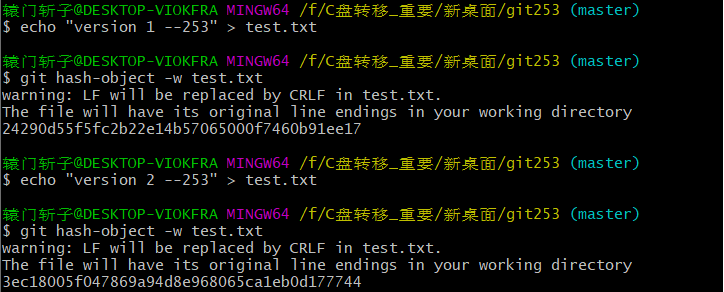
此时查看 objects 目录,可以发现:两个版本的 test.txt 文件皆存在;查看 git253 目录,可以发现:存在 test.txt 文件,且其内容为 “version 2 –253”。
随后删除 git253 目录中 test.txt 文件,随后使用 objects 目录中 test.txt 文件进行恢复,可以看到恢复成功。

至此,我们已基本了解:文件如何存储于 Git 数据库,且其以何种方式存储于 Git 数据库。然而,我们需要注意两点:记住每个文件每个版本的 SHA-1 散列值并不现实、基于命令 git hash-object ,我们仅存储其内容,而没有存储其对应文件名。
基于
git hash-object得到的数据对象,Git 中称为blob类型数据。使用命令git cat-file -t <hash>,我们可查看指定内容的具体类型。
tree object
git object 解决了数据存储问题,tree object 则解决了数据对应文件名的存储问题。
tree object 就是一棵树,其中存储若干树记录 tree entry。对于每条记录而言,其存储指向 tree object 或 git object 的 SHA-1 散列值以及相应内容的文件模式类型 (不同文件具有不同的模式类型,例如:100644 表示普通文件、100755 表示可执行文件、120000 表示符号链接、040000 表示目录)、文件类型 (Git 数据库中存储的实际类型,git object 对应 blob,tree object 对应 tree)、文件名。
命令 git cat-file -p master^{tree} 用于查看当前分支最新提交所对应的 tree object:

我们使用图例形象化表示此 tree object:
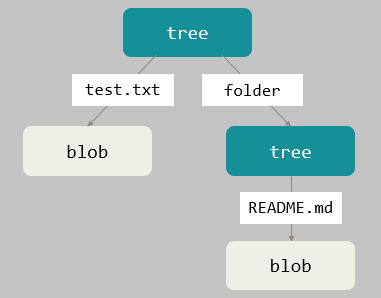
事实上,Git 会根据某时刻暂存区状态使用命令 git write-tree 自动创建一个 tree object,并返回相应的 SHA-1 散列值。
commit object
就本质而言,tree object 便是 项目快照。如果我们想使用项目快照,就需要完全记住各项目快照所对应的 SHA-1 散列值。而这并不现实,因此 Git 使用 commit-object 保存项目快照信息。
commit-object 表示为一个提交记录,其中包含待提交的 tree object、父提交 commit-object、提交者姓名、提交者电子邮件、提交时间戳、提交说明。底层命令 git commit-tree <tree-object-hash> -p <parent-hash> -m <commit-message> 可用于手动创建一个提交记录,并返回相应的 SHA-1 散列值。
tag object
相比上面三种对象而言,tag object 显得可有可无。由于附注标签需要存储多种信息,因此底层实现中使用 tag object 进行存储。
对于 tag object 而言,其中包含提交者姓名、提交者电子邮件、提交时间戳、提交说明、某 commit object的 SHA-1 散列值。
对于
tag object而言,其可以不提交某commit object的SHA-1散列值,转而提交其他信息,例如某git object的SHA-1散列值。
对象存储
我们在此简要描述 Git 存储对象的具体过程:
基于待存储数据内容,计算头部信息 header。header 共分为四大部分,具体如下:
获取待存储数据类型 (
blob、tree或commit),并以此作为 header 的第一部分内容。空格作为 header 的第二部分内容。
获取待存储数据长度,并以此作为 header 的第三部分内容。
空字节作为 header 的第四部分内容。
举例而言,对于文本串
what is up, doc?而言,其对应 header 为blob 16 \0。将 header 与待存储数据内容拼接起来,计算其
SHA-1散列值 (它将作为存储数据的唯一标识返回)。使用 zlib 压缩待存储数据,并基于路径构建原则 “``SHA-1` 散列值的前 2 个字符作为子目录名称,后 38 个字符则作为子目录内待存储数据对应的文件名” ,将数据存储至其中。需要注意:如果子目录或指定文件不存在,则创建相应内容,随后写入数据。如果指定文件存在,则重写之。
基于上面所得知识,可以知道:当使用命令 git add 添加工作区文件至暂存区时,Git 一定会将修改过的文件添加到 objects 目录中 (即使该文件曾经已经被添加至 objects 目录,但是由于内容不同,故而需要再次添加)。这样就会引申出一个问题:当频繁使用命令 git add 后,objects 目录将会存在同一文件的众多版本。这种情况将会使得 objects 目录所占空间迅速增大,那么 Git 是如何解决此问题的?
与其他集中式版本控制系统类似,Git 基于保存文件差异实现压缩空间。具体而言,最初 zlib 压缩所采用的格式为 松散对象格式。当目录中松散格式文件过多、向远程服务器推送项目、或者手动输入命令 git gc 时,Git 会根据文件名和文件大小将松散格式文件打包为若干基于二进制存储的 包文件。
包文件存在于 objects/pack 目录之下,每个包文件具体对应两个文件 —— xxx.idx 索引文件和 xxx.pack 存储对象打包文件,其中 xxx.pack 存储相关对象的打包结果,xxx.idx 存储各数据对象在打包文件中的偏移位置。
objects/info目录存储一些附加信息,似乎不太重要。
refs 目录
当需要查看特定提交记录的具体内容时,我们可以直接使用相应的 SHA-1 散列值进行获取,但是这种方法比较繁琐。如果我们可以使用别名替代 SHA-1 散列值,则该操作将变得简单、易用。在 Git 中,它使用 引用 (ref) 达成此效果,其实质在于:在特定位置存放与引用名同名的文件,该文件中存放特定提交记录的 SHA-1 散列值。当使用引用时,Git 会自动将其替换为该引用所对应文件中的 SHA-1 散列值。
Git 中所有引用文件均位于 refs 目录,这些引用文件分别对应于分支 (其均位于 .git/refs/heads)、标签 (其均位于 .git/refs/tags)、远程跟踪分支 (其均位于 .git/refs/remotes)。

按照 Git 引用原理,我们可通过写入一个 SHA-1 散列值至文件,从而得到该散列值的引用,其具体命令为 echo <hash> > ./git/refs/heads/<fileName>。
由于直接编辑文件比较危险,Git 提供命令 git update-ref <refName> <commit-id> 以更新指定文件内容,其中 refName 具体为 refs/**。举例:命令 git update-ref refs/heads/master 1a410。
branch ref
Git 引用原理已经知晓,我们在此说明分支引用的若干操作原理:
git branch <branchName>Git 首先基于
HEAD指针获取当前分支的最新提交记录 ID,随后新建文件refs/heads/<branchName>,并将此 ID 写入其中。git checkout <branchName>假定当前分支名为
currBranName,Git 会将ref: refs/heads/currBranName写入HEAD文件之中 (HEAD文件含义下见)。
tag ref
上面已经提及 tag object 和 Git 引用原理,那么 tag ref 应该就比较好理解了:
- 如果为轻量标签,则其
ref/tags/<tagName>内容为某commit object的SHA-1散列值。 - 如果为附注标签,则其
ref/tags/<tagName>内容为某tag object的SHA-1散列值。
remote ref
remote ref 指代远程跟踪分支,其引用原理已经介绍,与本地分支的区别也已经介绍,所以就没什么可说的了。
HEAD 文件
在之前文章中,我们提及 HEAD 指针指代当前项目具体位于哪一分支。HEAD 文件其实就是这个 HEAD 指针,其内容便指明当前项目具体位于哪一分支。为理解这些话,只要查看本地文件 .git/HEAD 即可:

我们可直接编辑该文件以修改 HEAD 指针指向,Git 同样提供命令 git symbolic-ref HEAD [<refname>/<commit-id>] 以修改 HEAD 指针指向。
根据上文,我们知道:命令 git checkout 同样具有修改 HEAD 指针的作用。如果使用命令 git checkout <commit-id>,HEAD 指针便不再指向具体分支,而是指向具体 SHA-1 散列值,此时 Git 将报警 “ You are in ‘detached HEAD’ state.”。
index 文件
该文件保存暂存区的文件信息。它是一个二进制文件,无法直接查看具体内容,因此我们在此仅说明其内容组成:
header 部分
共计 12 字节。前四字节标识该文件是否为合法 index 文件;中间四字节标识 index 文件的版本类型;后四字节标识暂存区内所管理的文件数量。
条目部分
条目部分用于记录暂存区内的文件信息。每一个条目具体对应于一个文件,不同条目之间使用 8 个连续的 0 进行分隔。
针对一个条目而言,其包括如下内容:
- 8 字节的文件创建时间、8 字节的文件修改时间
- 4 字节的文件存储设备号、4 字节的文件存储 inode 号
- 4 字节的文件权限描述
- 4 字节的 UID (User ID)、4 字节的 GID (Group ID)
- 4 字节的文件大小
- 20 字节的文件 SHA-1 哈希值 (用于指代对应文件在 .git/objects 目录中的位置)
- 2 字节的状态信息 (包括假定不变标识符、阶段标识、文件名长度等)
- 若干字节的文件路径信息
目录索引
目录索引用于存放目录信息,以实现快速重建工作目录。
校验值
20 字节的 index 文件校验值。