数据结构-LSM树
概述
LSM 树 是一种文件组织数据结构,它常用作非关系型数据库的底层实现 (B+ 树则常用作关系型数据库的底层实现)。
通常情况下,数据读取需求大于数据写入需求,故而产生了 B+ 树这种文件组织结构。由于物联网地兴起,数据写入需求大于数据读取需求的情况发生,此时如果仍然使用 B+ 树组织文件,则性能较差,故而产生了 LSM 树这种文件组织结构。
我们首先看看磁盘访问性能比较图:
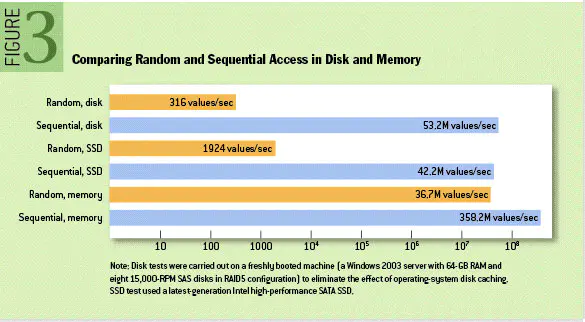
观察该图,容易得知:磁盘顺序访问性能远大于磁盘随机访问性能,且甚至超越了内存随机访问性能。正是基于这一点观察,LSM 树将磁盘随机访问操作转换为磁盘顺序访问操作,从而使得随机写操作性能大大提升,与之对应的便是随机读性能有所下降 (可通过布隆过滤器等操作弥补随机读性能)。
LSM 树
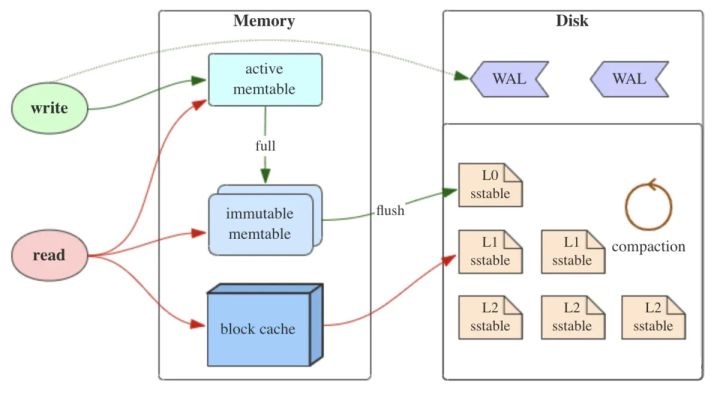
LSM 树通常由三部分组成:
memtable
它是位于内存之中的数据结构,用于存储最近更新地数据,而且这些数据按照键值有序排列,故而 memtable 通常表现为红黑树、跳跃表等高效排序结构。
由于内存属于不稳定介质,故而插入元素至 memtable 之前,需通过 WAL(Write-ahead logging) 将其插入至日志之中,以保证数据的可靠性。
immutable memtable
它是位于内存之中、不可修改的数据结构。它是将 memtable 转变为 sstable 的中间状态,其目的在于:转存过程中仍然可以通过 memtable 进行写操作。
sstable
它是有序键值对集合,是位于磁盘之中的数据结构。如果希望加快 sstable 读取性能,可为其建立索引或使用布隆过滤器。

接下来简单介绍其上的插入、删除、查询、修改操作。
插入
为保证数据完整性,首先需要基于 WAL 将数据插入至日志之中,随后将其插入至 memtable 之中。如果 memtable 所存数据量超过阈值,则需要将其转换为 immutable memtable,随后 immutable memtable 又将转存为 sstable。如果 sstable 数量过多,则需要进一步合并 sstable。
如果单纯仅转存为 sstable,如此将会引入大量 sstable,此时查找性能将大大下降,故而需要根据一定规则适当合并 sstable (合并规则是 LSM 树的重中之重)。
删除
如果直接删除待删除元素,这样会直接导致磁盘内容发生变更,不利于顺序访问磁盘。
为删除一个元素,我们需要将其关键字及删除标志插入至 LSM 树中。当 sstable 合并时,此时根据删除标志将该元素删去。
查询
查询操作比较复杂,从上述结构中可以看到:memtable 中数据最新、immutable memtable 中数据其次、sstable 中数据最旧。
当进行查询操作时,我们首先在 memtable 中进行查找,如果找到则返回,否则继续查找 immutable memtable,最后查找 sstable。
修改
与删除操作类似,修改操作亦是基于插入操作实现。
为修改一个元素,我们需要将其关键字及修改内容插入至 LSM 中。当 sstable 合并时,将关键字对应数据内容更新至最新内容即可。
合并策略
从 LSM 树的各项操作中,可以看到:所有操作中都涉及合并操作,故而合并策略就显得尤为重要。
在介绍合并策略之前,首先介绍三个概念:
读放大
读取数据时实际读取地数据量大于真正地数据量。例如:在 LSM 树中需要先在 memtable 查看指定关键字是否存在,不存在继续从immutable memtable、sstable 中寻找。
写放大
写入数据时实际写入的数据量大于真正地数据量。例如:在 LSM 树中写入数据引发合并操作,合并操作将会涉及大量写入。
空间放大
数据实际占用的磁盘空间大于真正地数据量。例如:在 LSM 树中,由于删除、修改操作均基于插入实现,故而将会引入大量重复关键字及其对应数据。
接下来我们介绍两种合并策略:size-tiered 和 leveled。
size-tiered
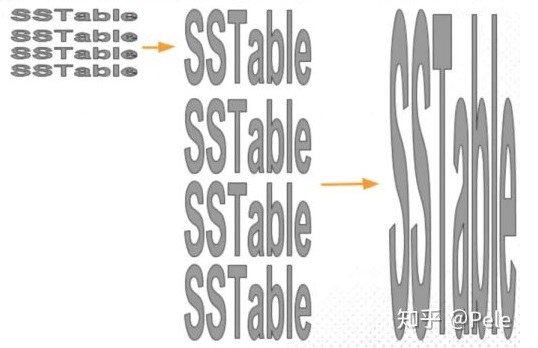
size-tiered 策略对 sstable 进行分级,如果当前层级 sstable 个数超过阈值,则合并这些 sstable 以得到一个更高层级的 sstable。容易得知:sstable 层级越高,其所含数据越多,对应文件就越大。
在这种策略中,同一层级的 sstable 可以包含具有相同关键字的数据,这使得耗费多余空间且存在过多旧副本,故而其空间放大问题较为严重,同时读放大问题较为严重。相比于下面的 leveled 策略而言,该种策略的写放大问题并不明显。
当进行合并时,首先顺序读取当前层级 sstable,然后按照外部归并排序操作依次合并,随后将合并结果 sstable 顺序存入磁盘之中。
leveled

leveled 策略基于层级文件大小进行分级,每一层级由若干 sstable 组成,而且这些 sstable 有序排列且互相不含相同关键字。
进行合并之时,如果某一层级文件大小超过阈值,则从中选择一个 sstable 并将其与下一层级中与此部分所含关键字存在交集部分的 sstable 合并,随机继续判断当前层级文件大小是否超过阈值,如果超过则继续选择 sstable 进行类似合并操作,否则递归判断下一层级文大小是否超过阈值。
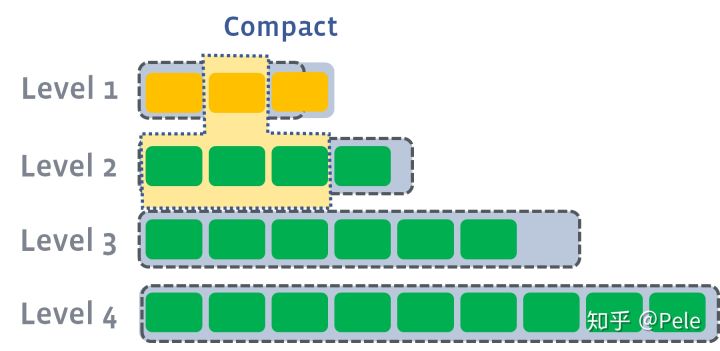
在这种策略中,同一层级的 sstable 不会包含具有相同关键字的数据,故而其空间放大问题及读放大问题得以缓解。但是其合并策略可能使得写放大问题较为严重,例如:某个层级文件大小超过阈值,而且选择合并的 sstable 所含关键字范围几乎囊括下一层级中所有 sstable,此时就涉及极大地写入问题。
LSM VS B+
这里简单比较 LSM 树和 B+ 树:
- 两者均为文件组织数据结构,用于处理大数据存取问题。
- 前者基于 “磁盘顺序访问性能远大于磁盘随机访问性能,且甚至超越了内存随机访问性能” 观察而产生,后者则基于 “磁盘随机访问性能较差,应当尽可能减少随机访问操作” 观察而产生。
- 前者适用于写多读少场景,后者则适用于写少读多场景。