字符编码
本文描述两种字符编码 ascii 和 unicode,并详解 unicode 编码的三种实现方式 utf-8、utf-16 和 utf-32。
ascii
上世纪60年代,美国制定了一套字符编码 ascii,对英文字符和二进制位之间定义了一个映射关系。
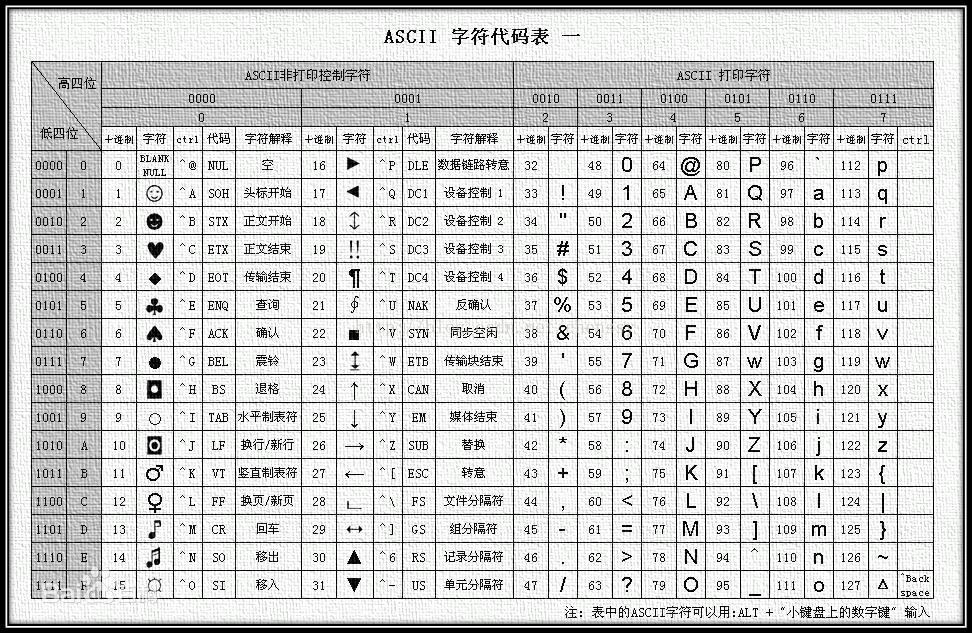
在 ascii 中,一个英文字符使用一个字节的二进制位进行表述。
ascii 仅对128个英文字符进行编码,因此一个字节的二进制位仅使用了 00000000~01111111。
非ascii
随着计算机的流行,其他国家也需要对其语言中的字符进行编码,通常做法是这样的——对 ascii 进行扩充,使用二进制位中的 10000000~11111111 表示其国家语言中的字符。
中文编码比较特殊,这里不考虑。
那么这样就会出现一个问题:二进制位中的 10000000~11111111 在不同国家的编码中表示不同的字符,如果以错误的字符编码打开一个文件,将会出现乱码?
为解决这个问题,需要制定一套字符编码,定义世界上所有字符与二进制位之间的映射关系,这种字符编码就是 unicode。
unicode
unicode 为世界上所有字符与二进制位之间定义了一个映射关系,形成一个巨大的字符集 。
unicode 的编码空间为 U+0000 ~ U+10FFFF,共可容纳 1112064 个字符。
unicode 定义了字符与二进制位之间的映射关系,但并没有规定如何存储这个二进制位。因此出现了众多 unicode 的实现方式,这里介绍三种——utf-8 、 utf-16 和 utf-32。
utf-8
utf-8 是一种变长字符编码,即字符集中不同字符,可能具有不同的字节长度 (1/2/3/4 字节)。
utf-8 的编码规则如下:
- 对于单字节字符,字节第一位置为
0,其余 7 位为该字符的unicode编码。因此对于英文字母, utf-8 编码结果与 ascii 是相同的。 - 对于
n字节字符,第一个字节的前n位置为1,n + 1位置为0,其余字节的前两位置为10,其余二进制位为该字符的unicode编码。
unicode 与 utf-8 之间的对应关系:
| unicode编码 | utf-8编码 |
|---|---|
| U+ 0000 ~ U+ 007F | 0XXXXXXX |
| U+ 0080 ~ U+ 07FF | 110XXXXX 10XXXXXX |
| U+ 0800 ~ U+ FFFF | 1110XXXX 10XXXXXX 10XXXXXX |
| U+10000 ~ U+10FFFF | 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX |
举一个例子:严 的 unicode编码 是 U+4E25,通过上面的对应关系,可以得知 严 的 utf-8 编码占三个字节,即格式为 1110XXXX 10XXXXXX 10XXXXXX。从最后一个二进制位开始,依次从后向前将 U+4E25 的二进制位填到X,多余的 X 填入 0,最终得到 严 的 utf-8 编码为 11100100 10111000 10100101。
utf-16
utf-16 是一种变长字符编码,即字符集中不同字符,可能具有不同的字节长度 (2/4 字节)。
utf-16 的编码规则比较麻烦,具体如下:
utf-16 将 unicode 的编码空间划分为 16 个平面。第
XX个平面的编码范围为0xXX0000 ~ 0xXXFFFF。第一个平面称为 基本多语言平面 ( 2字节 ) ,其余平面称为 辅助平面 ( 4字节 ) 。unicode 标准规定区间
U+D800 ~ U+DFFF不对应任何字符,因此 utf-16 使用这部分区间对辅助空间中的字符进行编码。在 基本多语言平面 中,
U+D800 ~ U+DFFF区间不对应任何字符,因此无需编码;U+0000 ~ U+D7FF和U+E000 ~ U+FFFF区间中的字符,其 utf-16 编码结果就是 unicode 编码。在 辅助平面 中,utf-16 将 区间
U+10000 ~ U+10FFFF中的字符编码为 代理对 。具体编码方式如下:
- 将 unicode 编码值减去
0x10000,得到一个值 (值范围为0x00000 ~ 0xFFFFF) 。 - 取该值高 10 位 (值范围为
0x00 ~ 0x3FF),加上0xD800得到 前导代理 (值范围为0xD800 ~ 0xDBFF) - 取该值低 10 位 (值范围为
0x00 ~ 0x3FF),加上0xDC00得到 后尾代理 (值范围为0xDC00 ~ 0xDFFF) - (前导代理,后尾代理) 即为 utf-16 编码结果。
- 将 unicode 编码值减去
举一个例子:𐐷 的 unicode编码为 U+10437。由于它在辅助平面,因此先减去 0x10000 得到 0000 0000 0100 0011 0111 , 取高 10 位 和低 10 位 分别处理得到 0xD800 + 0x0001 = 0xD801,0xDC00 + 0x0037 = 0xDC37,最终 utf-16 编码结果就是 0xD801 DC37。
utf-32
utf-32 是一种定长字符编码,即字符集中所有字符均编码为 4 字节。
utf-32 的编码规则十分简单,具体如下:
- 从低位到高位依次放置 unicode 编码,多余位置
0即可。